Show code cell content
import mmf_setup;mmf_setup.nbinit()
import logging;logging.getLogger('matplotlib').setLevel(logging.CRITICAL)
%matplotlib inline
import numpy as np, matplotlib.pyplot as plt
This cell adds /home/docs/checkouts/readthedocs.org/user_builds/physics-555-quantum-technologies/checkouts/latest/src to your path, and contains some definitions for equations and some CSS for styling the notebook. If things look a bit strange, please try the following:
- Choose "Trust Notebook" from the "File" menu.
- Re-execute this cell.
- Reload the notebook.
Weak Measurements#
The generalized Measurement formalism allows for a simplified discussion of weak measurements. The idea is to introduce a set of Kraus operators \(\{\mat{M}_{m}\}\) that are in some sense close to the identity \(\mat{M}_{m} \approx a\mat{1}\) (with a proportionality factor) such that the measurements do not completely collapse the state. Here we consider a simple example and explore how weak measurements can be used to advantage when interrogating quantum systems.
Single Qubit Example#
Consider the following weak measurements of \(\mat{Z}\):
where we call \(\epsilon\) the weakness parameter.
Do it! Implement these using projective measurements.
These can be implemented as strong measurements of the following operators, which make use of a single qubit ancillae. First define a unitary operator \(\mat{U}\) that behaves as follows
If \(\epsilon = 1\) (\(\alpha = 0\)), these correspond to the standard von Neumann measurement of \(\op{Z}\), but as \(\epsilon \rightarrow 0\) (\(\alpha \rightarrow 1\)), they provide less and less information about the state, but also cause less of a collapse. In the extreme limit \(\epsilon = 0\), we have \(\mat{M}_{+1} = \mat{M}_{-1} = \mat{1}/\sqrt{2}\), and the measurement leaves the state undisturbed, while providing absolutely no information.
To visualize what these measurements tell us, consider an initial state
with \(\theta \in [0, \pi]\). Measuring this state gives \(m \in \{+1, -1\}\) with probabilities
More succinctly:
What about the action of the measurement on the state? According to the postulate of generalized measurements, \(\ket{\psi} \rightarrow \mat{M}_{m}\ket{\psi}/\sqrt{p_m}\). Thus:
Since these \(\mat{M}_{\pm 1}\) commute (they are both diagonal), we can succinctly describe a series of \(n_{+}\) measurements with value \(m=+1\) and \(n_{-}\) measurements with value \(m=-1\):
Generalizing slightly and using rotational invariance, we will also consider measurements at an angle \(\vartheta\) – i.e. \(\vartheta=\pi/2\) corresponds to a weak measurement of \(\mat{X}\) – with probabilities:
Thus, the weak measurement has the effect of marching the state towards the measurement eigenstates, but with decreasing step size.
Random Walk on Bloch Sphere#
To make this behavior a little more explicit, it is useful to introduce some new variables:
Show code cell content
# Check some identities
theta = np.linspace(0, np.pi)[1:-1]
x = -np.log(np.tan(theta/2))
t2 = np.tan(theta/2)**2
assert np.allclose(np.tanh(x), np.cos(theta))
assert np.allclose(np.tanh(x), (1-t2)/(1+t2))
alpha = 0.123
eps = (1-alpha**2)/(1+alpha**2)
assert np.allclose(alpha**2, (1-eps)/(1+eps))
assert np.allclose(-np.log(alpha), np.arctanh(eps))
In terms of these variables, the evolution under these weak measurements is exactly that of a random walk with step size \(\delta\)
where \(m = \pm 1\) is a random variable with distribution that depends on \(x\):
Information and Bayes’ Theorem#
We now ask the question: What can we learn about a state by performing measurements. To make this definite, suppose we are given a quantum state \(\ket{\theta}\) known to lie in the \(x-z\) plane, but with some prior knowledge coded in the prior distribution \(p(\theta)\).
After making a measurement with outcome \(m\), we can characterize what we have learned by using Bayes’ theorem to get the posterior distribution
where \(p_\epsilon(m|\theta)\) is the likelihood of measuring \(m\) if the state is \(\ket{\theta}\).
Now consider a sequence of measurements giving results \(\vect{m} = [m_1, m_2, \cdots]\). Our posterior changes as:
where \(\theta_n\) characterizes the evolution of the state.
As a specific example, first consider a strong measurement along \(\vartheta = 0\) yielding the result \(m=\pm 1\) with a uniform prior \(p(\theta)=1/\pi\). The normalized posteriors are:
Show code cell source
# See how measuring successive m=0 results constraints the distribution
N = 200
thetas = np.linspace(0, np.pi, 2*N+1)[1:-1:2]
prior = 0*thetas + 1/np.pi
ps = [(1 + m*np.cos(thetas))/np.pi for m in [+1, -1]]
fig, ax = plt.subplots()
ax.plot(thetas, prior, ':k', label="prior")
ax.plot(thetas, ps[0], '-C0', label=r"$m=+1$")
ax.plot(thetas, ps[1], '-C1', label=r"$m=-1$")
ax.set(xlabel=fr"$\theta$",
ylabel=r"Posterior")
ax.legend();
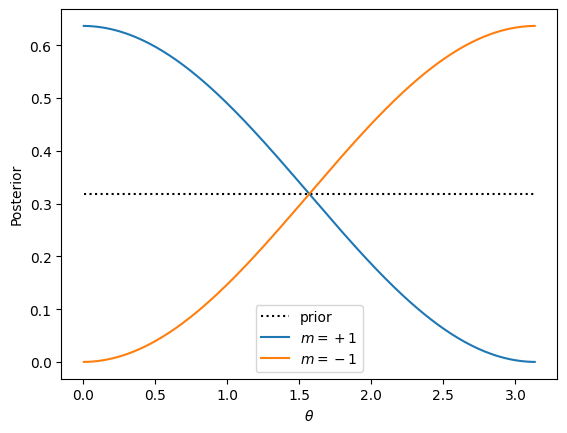
Now, suppose we start with state \(\ket{\theta=0} = \ket{0}\) (but we do not know this… we still assume our prior is uninformed \(p(\theta) = 1/\pi\)). In this particular case, a sequence of measurements will always give \(m = +1\). We must, however, still evolve \(\theta_n\) in our likelihood function: \(\tan\tfrac{\theta_{n}}{2} = \alpha^{n}\tan\tfrac{\theta}{2}\).
To Do.
The sympy code below shows that the product remains of the form \((a+\epsilon b\cos\theta)\), but I have not found a simple analytic way of computing the partial terms yet. Maybe these help?
Show code cell content
import sympy
eps, c = sympy.var('epsilon, c')
n = sympy.var('n', integer=True, positive=True)
a2 = (1-eps)/(1+eps)
res = (1-a2**n + (1+a2**n)*c)/(1+a2**n + (1-a2**n)*c)
ps = [(1+eps*res.subs(n, _n)).simplify() for _n in range(10)]
Ps = [ps[0]]
for _n in range(1, len(ps)):
Ps.append((Ps[-1] * ps[_n]).simplify())
display(Ps[-1])
Here are the results of performing a series of weak measurements in this case:
Show code cell source
# See how measuring successive m=0 results constraints the distribution
N = 200
thetas = np.linspace(0, np.pi, 2*N+1)[1:-1:2]
def likelihood(theta, epsilon, m=1):
"""Return the likelihood of measuring m, given a state |theta>"""
if m == -1:
epsilon *= -1
return (1 + epsilon*np.cos(theta))/2
def posterior(prior, epsilon, theta=thetas, m=1):
"""Return the posterior distribution.
Arguments
---------
prior : array-like
Prior distribution on theta in the initial state.
epsilon : float
Weakness parameter.
theta : float or array-like
Current values of theta. If several measurements have been performed, then the
final value of theta will differ from the original uniform thetas. This should
be used in this case to update the change in state.
"""
posterior = likelihood(theta=theta, epsilon=epsilon, m=m)*prior
posterior /= np.trapz(posterior, thetas)
return posterior
ps = [0*thetas + 1/np.pi]
theta = thetas
epsilon = 0.2
alpha = np.sqrt((1-epsilon)/(1+epsilon))
for n in range(10):
ps.append(posterior(prior=ps[-1], epsilon=epsilon, theta=theta, m=0))
theta = 2 * np.arctan(alpha * np.tan(theta/2))
fig, ax = plt.subplots()
for n, p in enumerate(ps):
ax.plot(thetas, p, ':', label=f"$n={n}$")
p0 = posterior(ps[0], epsilon=1, theta=thetas, m=0)
ax.plot(thetas, p0, '-k', label=r"$\epsilon=1$")
p1 = posterior(ps[0], epsilon=1, theta=thetas, m=1)
ax.plot(thetas, p1, '-k', label=fr"$\epsilon=1$, $H(p‖p_0)={H(p1, p0):.2f}$")
ax.set(xlabel=fr"$\theta$",
ylabel=r"Posterior $p(\theta)$ after $n$ measurements",
title=fr"$\epsilon={epsilon}$")
ax.legend();
/tmp/ipykernel_3976/2053297177.py:27: DeprecationWarning: `trapz` is deprecated. Use `trapezoid` instead, or one of the numerical integration functions in `scipy.integrate`.
posterior /= np.trapz(posterior, thetas)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[5], line 48
46 ax.plot(thetas, p0, '-k', label=r"$\epsilon=1$")
47 p1 = posterior(ps[0], epsilon=1, theta=thetas, m=1)
---> 48 ax.plot(thetas, p1, '-k', label=fr"$\epsilon=1$, $H(p‖p_0)={H(p1, p0):.2f}$")
49 ax.set(xlabel=fr"$\theta$",
50 ylabel=r"Posterior $p(\theta)$ after $n$ measurements",
51 title=fr"$\epsilon={epsilon}$")
52 ax.legend();
NameError: name 'H' is not defined
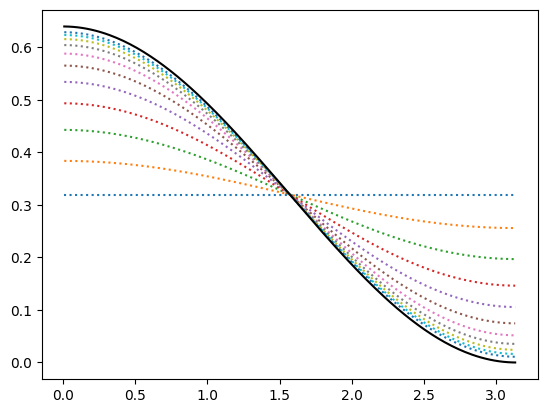
We see that a sequence of weak measurements approaches the result of a single strong measurement (or a sequence of strong measurements since a sequence is equivalent to a single strong measurement). Thus, in this case, weak measurements provide no advantage over a strong measurement.
Information Theory I#
How might we characterize: “how much we learn” by making these measurements? One way is to use the von Neumann entropy of the distribution:
Incomplete…#
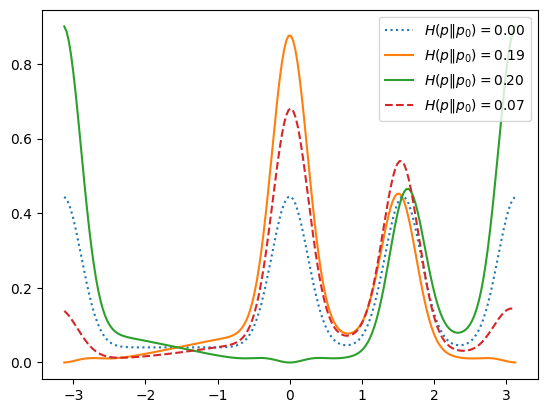
Where might we gain an advantage? Perhaps if the prior is not uniform: weak measurements would allow one to check several different directions, whereas a strong measurement would collapse the system. To consider this, we use the same system where the actual underlying state is \(\ket{0}\), but now suppose we have two independent particles that we can measure. To be precise:
We have an underlying system of particles in the state \(\ket{0}\), but with a flat prior.
We consider making different measurements with the detector at angle \(\vartheta_{n}\), recording the results as \(m_{n}\) or \(s_n = 1-2m_n\). Using rotational invariance, we can deduce that the likelihood of measuring \(s\) with the detector at angle \(\vartheta\) and the state at angle \(\theta\) is:
\[\begin{gather*} p_{\alpha,\vartheta}(s|\theta) = p_{\alpha}(s|\theta-\vartheta) = \frac{1}{2}\left( 1 + s\frac{1-\alpha^2}{1+\alpha^2}\cos(\theta-\vartheta) \right) \end{gather*}\]
The posterior after making the \(n\in\{1, 2, \cdots\}\) strong measurements with results \(\vect{s} = (s_1, s_2, \dots, s_n)\) is:
Consider now a measurement of the second particle in the direction of \(\theta^{m}_2\). The posterior now is:
Show code cell source
from scipy.special import xlogy
_TINY = np.finfo(float).tiny
def likelihood(theta, vartheta, epsilon, m):
"""Return the likelihood of measuring m, given a state |theta>"""
if m == -1:
epsilon *= -1
return (1 + epsilon*np.cos(theta-vartheta))/2
def measure(theta, vartheta, epsilon, m):
"""Perform the specified measurement and return the new theta."""
alpha = np.sqrt((1-epsilon)/(1+epsilon))
return vartheta + 2*np.arctan(alpha ** m * np.tan((theta-vartheta)/2))
def get_posterior(theta, epsilon, ms, varthetas):
thetas = theta
post = 0*thetas + 1/np.pi
for m, vartheta in zip(ms, varthetas):
kw = dict(theta=thetas, vartheta=vartheta, epsilon=epsilon, m=m)
post = post * likelihood(**kw)
thetas = measure(**kw)
return post
rng = np.random.default_rng(seed=4)
def doit(theta, epsilon, N=10):
"""Do a series of measurements."""
ms = []
varthetas = []
vartheta = 0
for n in range(N):
p0 = likelihood(theta, vartheta=vartheta, epsilon=epsilon, m=1)
m = 1 if rng.random() < p0 else -1
varthetas.append(vartheta)
ms.append(m)
if m == -1:
vartheta = np.pi/2 - vartheta
return ms, varthetas
def H(p, p0, theta=thetas):
"""Return the relative entropy H(p‖p_0)."""
return np.trapz(xlogy(p, p/(p0+_TINY)), theta)
N = 200
thetas = np.linspace(-np.pi, np.pi, 2*N+1)[1:-1:2]
# Uninformed prior for comparison.
p0 = 0*thetas + 1/2/np.pi
ps = [p0]
theta = thetas
epsilon = 0.2
alpha = np.sqrt((1-epsilon)/(1+epsilon))
P0 = get_posterior(thetas, epsilon=1, ms=[1], varthetas=[0])
P1 = get_posterior(thetas, epsilon=1, ms=[-1], varthetas=[0])
ms, varthetas = doit(theta=np.pi/2, epsilon=epsilon, N=100)
P = get_posterior(thetas, epsilon=epsilon, ms=ms, varthetas=varthetas)
sigma = 1/4
p0 = (np.exp(-thetas**2/2/sigma**2)
+ np.exp(-(thetas-np.pi/2)**2/2/sigma**2)
+ np.exp(-(thetas-np.pi)**2/2/sigma**2)
+ np.exp(-(thetas+np.pi)**2/2/sigma**2)
) + 0.1
p0 /= np.trapz(p0, thetas)
P0 *= p0
P1 *= p0
P *= p0
P0 /= np.trapz(P0, thetas)
P1 /= np.trapz(P1, thetas)
P /= np.trapz(P, thetas)
plt.plot(thetas, p0, ':', label=f"$H(p‖p_0)={H(p0, p0):.2f}$")
plt.plot(thetas, P0, label=f"$H(p‖p_0)={H(P0, p0):.2f}$")
plt.plot(thetas, P1, label=f"$H(p‖p_0)={H(P1, p0):.2f}$")
plt.plot(thetas, P, '--', label=f"$H(p‖p_0)={H(P, p0):.2f}$")
plt.legend();
/tmp/ipykernel_3976/984981411.py:14: RuntimeWarning: divide by zero encountered in scalar power
return vartheta + 2*np.arctan(alpha ** m * np.tan((theta-vartheta)/2))
/tmp/ipykernel_3976/984981411.py:68: DeprecationWarning: `trapz` is deprecated. Use `trapezoid` instead, or one of the numerical integration functions in `scipy.integrate`.
p0 /= np.trapz(p0, thetas)
/tmp/ipykernel_3976/984981411.py:73: DeprecationWarning: `trapz` is deprecated. Use `trapezoid` instead, or one of the numerical integration functions in `scipy.integrate`.
P0 /= np.trapz(P0, thetas)
/tmp/ipykernel_3976/984981411.py:74: DeprecationWarning: `trapz` is deprecated. Use `trapezoid` instead, or one of the numerical integration functions in `scipy.integrate`.
P1 /= np.trapz(P1, thetas)
/tmp/ipykernel_3976/984981411.py:75: DeprecationWarning: `trapz` is deprecated. Use `trapezoid` instead, or one of the numerical integration functions in `scipy.integrate`.
P /= np.trapz(P, thetas)
/tmp/ipykernel_3976/984981411.py:43: DeprecationWarning: `trapz` is deprecated. Use `trapezoid` instead, or one of the numerical integration functions in `scipy.integrate`.
return np.trapz(xlogy(p, p/(p0+_TINY)), theta)
vartheta = np.pi/2
theta = np.pi/3
for n in range(10):
print(theta)
theta = measure(theta, vartheta=vartheta, epsilon=epsilon, m=1)
1.0471975511965976
1.140024432184815
1.2172596758834402
1.281132686307852
1.3337357304245163
1.3769350069520372
1.4123439785134186
1.4413302969180168
1.4650385386002653
1.484418626293319
Show code cell source
'''
for n in range(9):
ps.append(posterior(prior=ps[-1], epsilon=epsilon, theta=theta, m=0))
theta = 2 * np.arctan(alpha * np.tan(theta/2))
fig, ax = plt.subplots()
for n, p in enumerate(ps):
ax.plot(thetas, p, ':', label=f"$n={n}$, $H(p‖p_0)={H(p, p0):.2f}$")
p1 = posterior(ps[0], epsilon=1, theta=thetas, m=0)
ax.plot(thetas, p1, '-k', label=fr"$\epsilon=1$, $H(p‖p_0)={H(p1, p0):.2f}$")
ax.set(xlabel=fr"$\theta$",
ylabel=r"Posterior $p(\theta)$ after $n$ measurements",
title=fr"$\epsilon={epsilon}$")
ax.legend();
'''
'\nfor n in range(9):\n ps.append(posterior(prior=ps[-1], epsilon=epsilon, theta=theta, m=0))\n theta = 2 * np.arctan(alpha * np.tan(theta/2))\n\n\nfig, ax = plt.subplots()\nfor n, p in enumerate(ps):\n ax.plot(thetas, p, \':\', label=f"$n={n}$, $H(p‖p_0)={H(p, p0):.2f}$")\n\np1 = posterior(ps[0], epsilon=1, theta=thetas, m=0)\nax.plot(thetas, p1, \'-k\', label=fr"$\\epsilon=1$, $H(p‖p_0)={H(p1, p0):.2f}$")\nax.set(xlabel=fr"$\theta$", \n ylabel=r"Posterior $p(\theta)$ after $n$ measurements",\n title=fr"$\\epsilon={epsilon}$")\nax.legend();\n'