Weak Measurements#
The generalized Measurement formalism allows for a simplified discussion of weak measurements. The idea is to introduce a set of Kraus operators \(\{\mat{M}_{m}\}\) that are in some sense close to the identity \(\mat{M}_{m} \approx a\mat{1}\) (with a proportionality factor) such that the measurements do not completely collapse the state. Here we consider a simple example and explore how weak measurements can be used to advantage when interrogating quantum systems.
Single Qubit Example#
Consider the following weak measurements of \(\mat{Z}\):
where we call \(\epsilon\) the weakness parameter.
Do it! Implement these using projective measurements.
These can be implemented as strong measurements of the following operators, which make use of a single qubit ancillae. First define a unitary operator \(\mat{U}\) that behaves as follows
If \(\epsilon = 1\) (\(\alpha = 0\)), these correspond to the standard von Neumann measurement of \(\op{Z}\), but as \(\epsilon \rightarrow 0\) (\(\alpha \rightarrow 1\)), they provide less and less information about the state, but also cause less of a collapse. In the extreme limit \(\epsilon = 0\), we have \(\mat{M}_{+1} = \mat{M}_{-1} = \mat{1}/\sqrt{2}\), and the measurement leaves the state undisturbed, while providing absolutely no information.
To visualize what these measurements tell us, consider an initial state
with \(\theta \in [0, \pi]\). Measuring this state gives \(m \in \{+1, -1\}\) with probabilities
More succinctly:
What about the action of the measurement on the state? According to the postulate of generalized measurements, \(\ket{\psi} \rightarrow \mat{M}_{m}\ket{\psi}/\sqrt{p_m}\). Thus:
Since these \(\mat{M}_{\pm 1}\) commute (they are both diagonal), we can succinctly describe a series of \(n_{+}\) measurements with value \(m=+1\) and \(n_{-}\) measurements with value \(m=-1\):
Generalizing slightly and using rotational invariance, we will also consider measurements at an angle \(\vartheta\) – i.e. \(\vartheta=\pi/2\) corresponds to a weak measurement of \(\mat{X}\) – with probabilities:
Thus, the weak measurement has the effect of marching the state towards the measurement eigenstates, but with decreasing step size.
Random Walk on Bloch Sphere#
To make this behavior a little more explicit, it is useful to introduce some new variables:
In terms of these variables, the evolution under these weak measurements is exactly that of a random walk with step size \(\delta\)
where \(m = \pm 1\) is a random variable with distribution that depends on \(x\):
Information and Bayes’ Theorem#
We now ask the question: What can we learn about a state by performing measurements. To make this definite, suppose we are given a quantum state \(\ket{\theta}\) known to lie in the \(x-z\) plane, but with some prior knowledge coded in the prior distribution \(p(\theta)\).
After making a measurement with outcome \(m\), we can characterize what we have learned by using Bayes’ theorem to get the posterior distribution
where \(p_\epsilon(m|\theta)\) is the likelihood of measuring \(m\) if the state is \(\ket{\theta}\).
Now consider a sequence of measurements giving results \(\vect{m} = [m_1, m_2, \cdots]\). Our posterior changes as:
where \(\theta_n\) characterizes the evolution of the state.
As a specific example, first consider a strong measurement along \(\vartheta = 0\) yielding the result \(m=\pm 1\) with a uniform prior \(p(\theta)=1/\pi\). The normalized posteriors are:
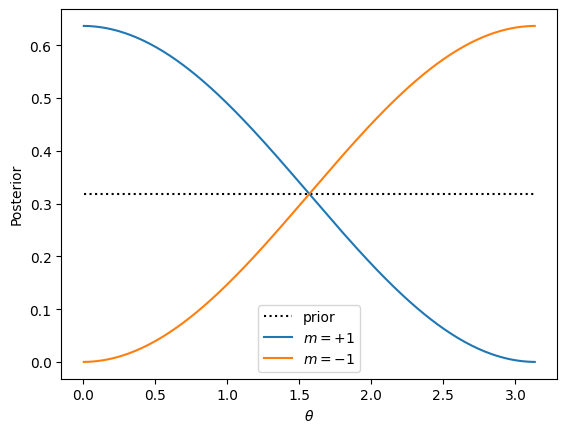
Now, suppose we start with state \(\ket{\theta=0} = \ket{0}\) (but we do not know this… we still assume our prior is uninformed \(p(\theta) = 1/\pi\)). In this particular case, a sequence of measurements will always give \(m = +1\). We must, however, still evolve \(\theta_n\) in our likelihood function: \(\tan\tfrac{\theta_{n}}{2} = \alpha^{n}\tan\tfrac{\theta}{2}\).
To Do.
The sympy code below shows that the product remains of the form \((a+\epsilon b\cos\theta)\), but I have not found a simple analytic way of computing the partial terms yet. Maybe these help?
Here are the results of performing a series of weak measurements in this case:
/tmp/ipykernel_4166/2053297177.py:27: DeprecationWarning: `trapz` is deprecated. Use `trapezoid` instead, or one of the numerical integration functions in `scipy.integrate`.
posterior /= np.trapz(posterior, thetas)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[5], line 48
46 ax.plot(thetas, p0, '-k', label=r"$\epsilon=1$")
47 p1 = posterior(ps[0], epsilon=1, theta=thetas, m=1)
---> 48 ax.plot(thetas, p1, '-k', label=fr"$\epsilon=1$, $H(p‖p_0)={H(p1, p0):.2f}$")
49 ax.set(xlabel=fr"$\theta$",
50 ylabel=r"Posterior $p(\theta)$ after $n$ measurements",
51 title=fr"$\epsilon={epsilon}$")
52 ax.legend();
NameError: name 'H' is not defined
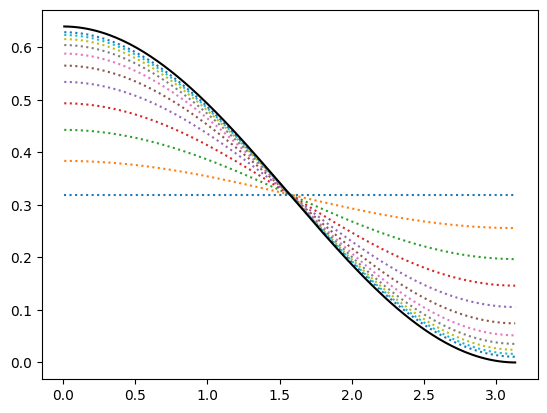
We see that a sequence of weak measurements approaches the result of a single strong measurement (or a sequence of strong measurements since a sequence is equivalent to a single strong measurement). Thus, in this case, weak measurements provide no advantage over a strong measurement.
Information Theory I#
How might we characterize: “how much we learn” by making these measurements? One way is to use the von Neumann entropy of the distribution:
Incomplete…#
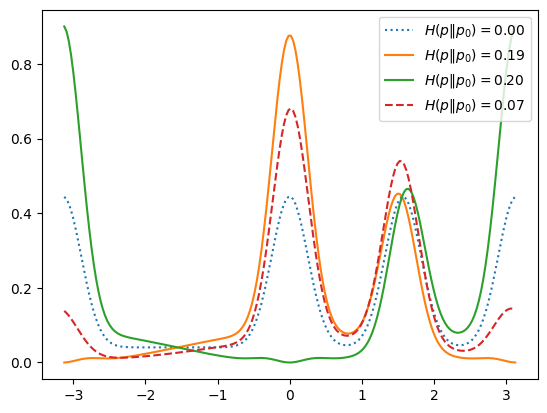
Where might we gain an advantage? Perhaps if the prior is not uniform: weak measurements would allow one to check several different directions, whereas a strong measurement would collapse the system. To consider this, we use the same system where the actual underlying state is \(\ket{0}\), but now suppose we have two independent particles that we can measure. To be precise:
We have an underlying system of particles in the state \(\ket{0}\), but with a flat prior.
We consider making different measurements with the detector at angle \(\vartheta_{n}\), recording the results as \(m_{n}\) or \(s_n = 1-2m_n\). Using rotational invariance, we can deduce that the likelihood of measuring \(s\) with the detector at angle \(\vartheta\) and the state at angle \(\theta\) is:
\[\begin{gather*} p_{\alpha,\vartheta}(s|\theta) = p_{\alpha}(s|\theta-\vartheta) = \frac{1}{2}\left( 1 + s\frac{1-\alpha^2}{1+\alpha^2}\cos(\theta-\vartheta) \right) \end{gather*}\]
The posterior after making the \(n\in\{1, 2, \cdots\}\) strong measurements with results \(\vect{s} = (s_1, s_2, \dots, s_n)\) is:
Consider now a measurement of the second particle in the direction of \(\theta^{m}_2\). The posterior now is:
/tmp/ipykernel_4166/984981411.py:14: RuntimeWarning: divide by zero encountered in scalar power
return vartheta + 2*np.arctan(alpha ** m * np.tan((theta-vartheta)/2))
/tmp/ipykernel_4166/984981411.py:68: DeprecationWarning: `trapz` is deprecated. Use `trapezoid` instead, or one of the numerical integration functions in `scipy.integrate`.
p0 /= np.trapz(p0, thetas)
/tmp/ipykernel_4166/984981411.py:73: DeprecationWarning: `trapz` is deprecated. Use `trapezoid` instead, or one of the numerical integration functions in `scipy.integrate`.
P0 /= np.trapz(P0, thetas)
/tmp/ipykernel_4166/984981411.py:74: DeprecationWarning: `trapz` is deprecated. Use `trapezoid` instead, or one of the numerical integration functions in `scipy.integrate`.
P1 /= np.trapz(P1, thetas)
/tmp/ipykernel_4166/984981411.py:75: DeprecationWarning: `trapz` is deprecated. Use `trapezoid` instead, or one of the numerical integration functions in `scipy.integrate`.
P /= np.trapz(P, thetas)
/tmp/ipykernel_4166/984981411.py:43: DeprecationWarning: `trapz` is deprecated. Use `trapezoid` instead, or one of the numerical integration functions in `scipy.integrate`.
return np.trapz(xlogy(p, p/(p0+_TINY)), theta)
vartheta = np.pi/2
theta = np.pi/3
for n in range(10):
print(theta)
theta = measure(theta, vartheta=vartheta, epsilon=epsilon, m=1)
1.0471975511965976
1.140024432184815
1.2172596758834402
1.281132686307852
1.3337357304245163
1.3769350069520372
1.4123439785134186
1.4413302969180168
1.4650385386002653
1.484418626293319
'\nfor n in range(9):\n ps.append(posterior(prior=ps[-1], epsilon=epsilon, theta=theta, m=0))\n theta = 2 * np.arctan(alpha * np.tan(theta/2))\n\n\nfig, ax = plt.subplots()\nfor n, p in enumerate(ps):\n ax.plot(thetas, p, \':\', label=f"$n={n}$, $H(p‖p_0)={H(p, p0):.2f}$")\n\np1 = posterior(ps[0], epsilon=1, theta=thetas, m=0)\nax.plot(thetas, p1, \'-k\', label=fr"$\\epsilon=1$, $H(p‖p_0)={H(p1, p0):.2f}$")\nax.set(xlabel=fr"$\theta$", \n ylabel=r"Posterior $p(\theta)$ after $n$ measurements",\n title=fr"$\\epsilon={epsilon}$")\nax.legend();\n'